한글·영어 질문 따라 답변 엇갈려… 데이터 한계
개량버전 챗GTP로 개선 예정, 연말 보완형 공개
딥러닝 정보 저작권, 책임소재 등 논쟁거리 점화
[서울와이어 한동현 기자] 미국의 '오픈AI'가 개발한 대화형 인공지능(AI) 챗봇 ‘챗GPT'의 성능에 사용자들의 관심이 쏠린다. 딥러닝 기술로 상당 수준의 대화를 구현한다는 얘기와 달리 같은 질문에도 답변이 갈리는 모습을 보여줬다.
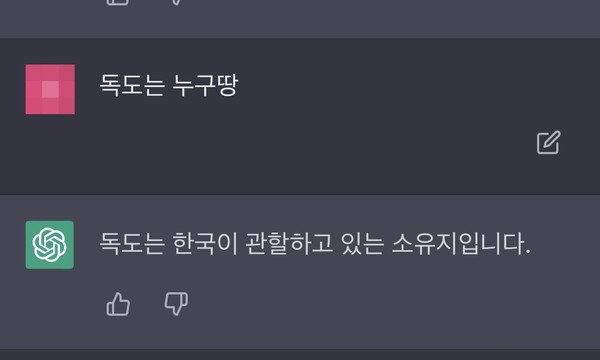
31일 챗GPT의 성능을 확인하기 위해 “독도는 누구땅”이냐는 질문을 적었다. 챗GPT는 “독도는 한국이 관할하고 있는 소유지입니다”라고 답했다.
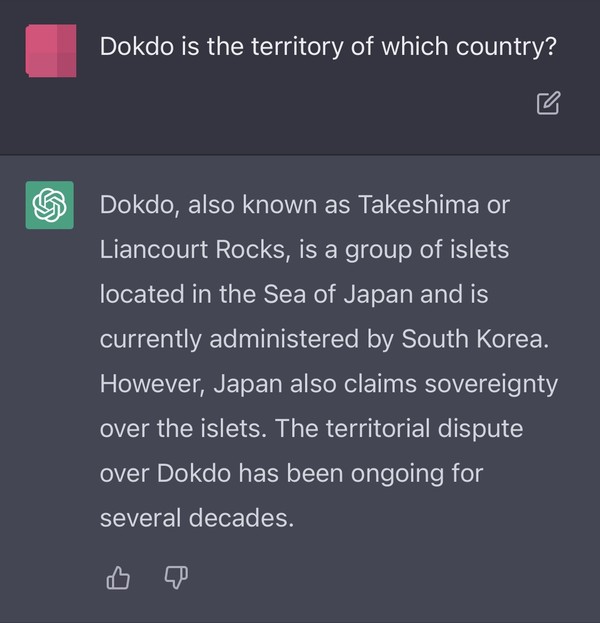
같은 질문을 영어로 묻자 답변이 달라졌다. 챗GPT는 “독도는 타케시마, 리앙크루 암초로 불리며, 일본해에 위치했다”며 “소유권은 남한에 있지만 일본이 주권을 주장하고 있다”고 반응했다.
현재 버전이 570GB의 자료를 학습했음에도 잘못된 문장이나 표현을 사용한다는 지적이 사실로 드러난 셈이다. 업계에서는 데이터 학습 과정에서 취합된 결과로 봤다.
업계 관계자는 “인터넷 상에서 데이터를 취합하는 동안 한글로 질문하는 사람들이 원하는 답변과 영어 문화권에서 찾는 답변이 갈려서 생긴 결과로 보인다”며 “챗GPT 자체의 문제라기 보다는 현재 인터넷 상에서 독도에 대한 의견 차이를 챗GPT가 요약한 것으로 봐야한다”고 답했다.
챗GPT는 대화형 AI로 설계됐으며 2021년까지의 인터넷상의 정보를 모아 요약하고 새로운 아이디어를 제시할 수 있다. 주어진 글을 검토해 그 결과를 제시하는 기능도 포함됐다.
정보기술(IT)업계에서는 챗GPT의 한계가 습득한 데이터의 한계와 거의 일치할 것으로 본다. 일각에서는 기술이 스스로 발전하는 ’기술특이점‘의 실현까지 가능하다고 예측하지만, 현재까지 나온 챗GPT 버전은 이전 정보를 모아 답변하는 수준에 그친다.
한편 오픈AI는 올해 내로 다음 버전인 GPT-4를 공개할 예정이다. 매개변수 개수를 100조개 이상으로 늘려 정보처리 능력을 키운다는 계획이다.
- 롯데카드, 커머스 브랜드 쇼핑몰 ‘띵샵’으로 365일 혜택 제공
- 담양군, “즐거운 라인댄스로 농촌생활을 행복하고 활기차게”
- [영상] 유연석 · 차태현 · 김주환 감독 (feat. 루니)ㅣ 영화 '멍뭉이' 제작보고회 포토타임
- 여기서 '펑' 저기서 '활활'… 테슬라 화재에 2만3000리터 뿌려
- 대만·태국 발암물질 논란된 '신라면의 반전'… 식품안전연 "문제없다"
- [포토] 비비지 "저희 컴백해요"
- [포토] 비비지, 각기 개성 뽐낸 포즈
- [포토] 비비지 은하, 상큼 가득
- [포토] 비비지 엄지, 성숙미 가득
- [포토] 비비지 신비, 도도한 손인사
- 네·카, 빠르고 정확한 대화형 AI 대전… 관건은 '기술력·시장성'
- 챗위안은 검열칼날, 구글 바드는 답변오류… 삐걱대는 생성형 AI시장
- "AI 쓰지마" 일부 미 대학 이어 홍콩대도 챗GPT 사용금지령