용량, 개방성 중심 차별화 시도
개발자 친화적모델, 참여확대기대
구글·MS 등과 경쟁, 후발주자 약점
[서울와이어 한동현 기자] 메타가 챗GPT 열풍에 동참한다. 생성형 인공지능(AI) 모델을 선보일 예정이며 개방성, 적은 용량 등으로 선발주자들과 경쟁할 계획이다.
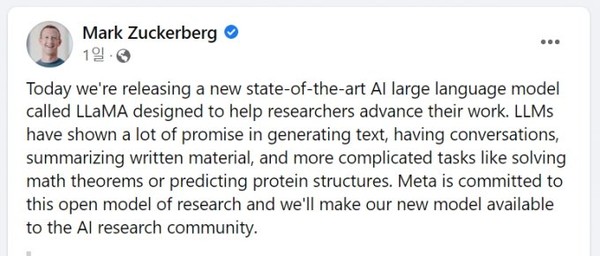
마크 저커버그 메타 최고경영자(CEO)는 24일(현지시간) 페이스북에 대규모 AI 언어 모델(LLM)인 ‘라마’(LLaMA)‘의 공개 계획을 밝혔다.
과학자와 엔지니어가 응용 프로그램을 개발할 수 있도록 비영리적 라이선스로 제공할 계획이다. 이는 이례적인 사례로 MS와 구글은 프로그램을 외부에 공개하지 않고 있다. 메타는 개발자들이 직접 프로그램을 사용하면서 모이는 데이터 활용에 집중할 것으로 보인다.
저커버그 CEO는 “LLM은 텍스트 생성·대화·문서 요약부터 수학 정리·단백질 구조 예측과 같은 복잡한 작업까지 가능성을 보여줬다”며 “메타는 개방적인 연구 모델에 전념하고 있고, 새로운 모델을 AI 연구 커뮤니티에 이용할 수 있도록 할 것”이라고 말했다.
메타는 경쟁사들 대비 활용성을 대폭 강조한 전략을 들고나왔다. 메타의 라마가 갖춘 매개변수는 650개에 불과하다. 이는 챗GPT에 적용된 GPT-3.5보다 적다. MS의 오픈AI가 1750억개 매개변수를 갖춘 것과 대조적이다.
메타는 매개변수의 수를 강점으로 내세웠다. 라마의 용량을 다른 모델 대비 10분의 1로 줄일 수 있기 때문이다. 모델을 모바일 환경에서도 다룰 수 있게 되면서 활용도를 대폭 늘릴 수 있다는 계산이다.
여기에 라이선스 비영리 제공까지 더해지면 외부 개발자들에 의한 라마 모델의 발전이 가능할 것으로 기대된다.
저커버그 CEO는 “더 큰 모델들이 능력을 확장해왔지만 운영 비용이 부담스러웠다”며 “람다는 다른 모델보다 훨씬 적은 컴퓨팅 파워가 필요하며 라틴어와 키릴 문자에 기반한 20개 언어로 구동된다”고 밝혔다.
업계에서는 상황을 지켜봐야 한다는 입장이다. 메타의 전략이 신선하기는 하지만 부실한 개발역량을 포장했다는 일각 비판도 있기 때문이다.
업계 관계자는 “구글이 바드를 내놓으면서 피해를 입은 사례를 보고 시장에 빠르게 진출해야겠다고 판단한 것으로 보인다“며 ”개발자들이 오픈 라이선스에 끌려 어떤 결과물을 내놓을 지는 기대가 된다“고 말했다.